
Jungeun Park
[논문 리뷰] MetaFormer is Actually What You Need for Vision 본문
Abstract
- Transformer는 vision 태스크에서 큰 잠재력을 보여줌
- Transformer의 높은 성능의 요인이 Attention 기반의 token mixer모듈이라고 여겨짐
- 그러나 최근 연구에 따르면 Transformer의 Attention 기반 모듈은 spatial MLP로 대체될 수 있으며 대체된 모델은 여전히 우수한 성능을 보임
- 이러한 관찰에 기초하여, 논문은 특정 token mixer 모델 대신 Transformer의 general 아키텍처가 모델의 성능에 더 필수적이라고 가정함
- 이를 검증하기 위해, 논문에서는 의도적으로 Transformer의 Attention 모듈을 매우 단순한 Pooling operator로 교체하여 가장 기본적인 token mixing만 수행함
- PoolFormer 모델이 여러 vision 태스크에서 경쟁력 있는 성능을 달성하며 논문의 가설 검증함
- PoolFormer의 효용성을 바탕으로, token mixer를 지정하지 않은 Transformer에서 추상화된 일반적인 구조인 MetaFormer의 개념을 시작할 것을 촉구함
- 광범위한 실험을 바탕으로, 우리는 MetaFormer가 비전 과제에 대한 최신 Transformer 및 MLP 유사 모델에 대한 우수한 성능을 달성하는 데 중요한 역할을 한다고 주장함
Introduction

- Transformer의 encoder는 두 개의 컴포넌트로 구성됨
- token mixer라고 불리는 토큰간의 정보를 mixing하는 attention 모듈
- channel MLPs나 residual connection과 같은 나머지 모듈→ attention 모듈을 특정 token mixer로 간주하여 general architecture인 Metaformer로 추상화함
- Transformer의 성공의 요인은 오랫동안 attention 기반의 token mixer라고 여겨짐
- 이로 인해 많은 attention 모듈에 대한 변형들이 제안됨
- Mlp-mixer는 token mixer로써 완전히 attention 모듈을 spatial MLPs로 대체한 모델을 제안하였고, 경쟁력있는 성능을 보임
- 후속 작업들도 data-efficient training 및 특정한 MLP 모듈 설계를 통해 MLP-like 모델을 더욱 개선하여 ViT와의 성능 격차를 점차 좁히고 attention기반 token mixer의 우위에 도전함
- 최근 몇몇 연구는 Metaformer 구조에서 다른 유형의 token mixer를 탐색하고 고무적인 성능을 보여줌
- FNet은 attention을 Fourier Transform 으로 대체하고 vanila tranformer와 비교해 97%의 정확도를 달성함
- 모든 결과를 종합하여, 논문은 모델의 성능에 있어서 결정적인 요인은 특정 token mixer가 아니라, general한 구조의 MetaFormer라고 가정함
- 이 가설을 검증하기 위해, 우리는 가장 기본적인 token mixing을 수행하기 위해 매우 단순한 non-parametic operator인 pooling을 적용함
- 놀랍게도, PoolFormer는 경쟁력 있는 성능을 달성하며, Transformer 및 MLP-like 모델의 성능도 지속적으로 능가함
Related Works
- 많은 연구들이 attention기반 token mixer의 우위에 도전하고 보다 나은 token mixer를 제안하는 것에 집중함
- 본 연구의 목적은 sota를 달성하기 위해 새로운 복잡한 token mixer를 설계하는 것이 아님
- 대신, 본 논문은 다음과 같은 근본적인 질문을 검토함
- Transformer와 그 변형의 성공에 대한 진정으로 책임이 있는 것은 무엇인가?
- 본 논문의 대답은 general architecture, 즉 MetaFormer이며 이를 증명하기 위해 pooling을 기본 token mixer로 활용함
- 몇몇 논문들은 동일한 질문에 답하고 있음
- Attention is not all you need: pure attention losses rank doubly exponentially with depth는 residual connection이나 MLP가 없으면 output matrix가 rank-1 matrix(query에 상관없이 모든 row가 동일해지는 matrix)로 수렴한다 것을 입증함
- Do vision transformers see like convolutional neural networks?는 ViT와 CNN의 특징 차이를 비교하여, self-attention이 글로벌 정보의 조기 집계를 가능하게 하는 반면, residual connection은feature를 하위 계층에서 상위 계층으로 강력하게 전파한다는 것을 발견함
→ 불행하게도, 이 작업들에서는 Transformer를 일반적인 구조로 추상화하지도 않고 Transformer 성능의 요인에 대한 명시적인 설명을 하지도 않음
Method
MetaFormer
- MetaFormer는 token mixer가 지정되지 않은 일반적인 아키텍처고, 다른 구성 요소들은 Transformer와 동일하게 유지됨
$$X=InputEmb(I)$$
- \(I\): input
- \(X \in R^{N×C}\), \(N\): sequence length, \(C\): embedding dimension
- 임베딩 토큰은 반복적으로 MetaFormer block으로 입력됨
- 각각은 두개의 residual sub block들을 포함함
- 첫 번째 sub block은 주로 토큰 간의 정보를 전달하는 토큰 믹서를 포함하며, 다음과 같이 표현됨
$$Y=TokenMixer(Norm(X))+X$$
- \(Norm() \): normalization (Layer Norm or Batch Norm)
- \(TokenMixer() \): 토큰 정보를 mixing하는 역할을 하는 모듈
- attention mechanism
- spatial MLP
- 두 번째 sub block은 주로 two-layered MLP + non-linear activation으로 구성됨
$$Z= \sigma(Norm(Y)W_1)W_2+Y$$
- \(W_1 \in R^{C×rC} \), \(W_2 \in R^{rC×C} \): learnable parameters
- \(r \): MLP expansion ratio
- \( \sigma() \): non-linear activation function (GLUE or ReLU)
Instantiations of MetaFormer
- MetaFormer는 token mixer의 구체적인 설계를 지정하는 것에 따라 Transformer(Attention)또는 MLP-like 모델(spatial MLP)이 될 수 있음
PoolFormer
- Transformer의 도입 이후, 많은 논문들이 Attention에 큰 중요성을 부여하고 다양한 Attention 기반 token mixer 모듈을 설계하는 데 초점을 맞추고 있음
- 대조적으로, 이러한 작업들은 general 아키텍처, 즉 MetaFormer에 거의 주의를 기울이지 않음
- 본 연구는 MetaFormer의 general 아키텍처가 최근 Transformer 및 MLP-like 모델의 성공 요인이라고 주장함
- 이를 입증하기 위해 일부러 당황스러울 정도로 간단한 연산자인 pooling을 token mixer로 사용함
- 학습 가능한 매개 변수가 없음
- 각 토큰이 인접 토큰 피쳐들을 평균적으로 집계하도록 함
$$T'{:,i,j}=\frac 1 {K×K} \sum^{K}{p,q=1} T_{:,i+p-\frac {K+1} 2, i+q - \frac {K+1} 2}-T_{:,i,j}$$
- \(K\): pooling size
- MetaFormer 블록은 이미 residual connection을 가지고 있기 때문에 입력을 뺌

- self-attention과 spatial MLP는 혼합할 토큰 수에 대한 계산 복잡도가 제곱
- 설상가상으로, spatial MLP는 긴 시퀀스를 처리할 때 훨씬 더 많은 파라미터를 가짐
- 이로 인해 self-attention과 spatial MLP는 일반적으로 수백 개의 토큰만 처리 가능함
- 대조적으로, pooling은 학습 가능한 매개 변수가 없고, 계산 복잡도는 시퀀스 길이에 linear함
- 따라서 우리는 기존의 CNN(AlexNet, VGG, ResNet) 및 최근의 계층적 Transformer 변형(Swin-T, PVT) 과 유사한 계층 구조를 채택하여 pooling을 활용함
- 특히, Poolformer에는 \( \frac H 4 × \frac W 4, \frac H 8 × \frac W 8, \frac H {16} × \frac W {16}, \frac H {32} × \frac W {32} \) 토큰의 4가지 단계가 있음

- 임베딩 크기는 두 그룹이 있음
- 임베딩 차원이 64, 128, 320, 512인 소형 모델
- 임베딩 차원이 96, 192, 384, 768인 중형 모델
- 총 \(L\)개의 PoolFormer 블록이 있다고 가정하면, 1, 2, 3, 4단계에는 각각 \( L/6, L/6, L/2, L/6\) 개의 PoolFormer 블록이 포함됨
- MLP expansion 비율은 4로 설정됨
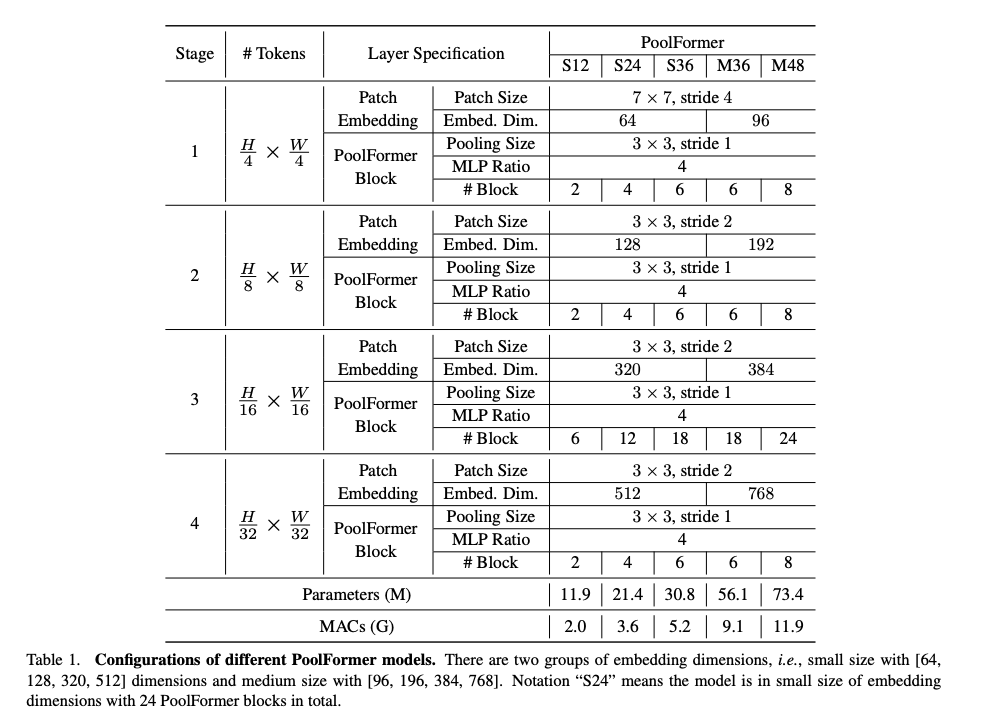
- 위에서 설명한 간단한 모델 스케일링 규칙에 따라, 논문에서는 5개의 서로 다른 모델을 구성함
Experiments
Image classification
Setup
- ImageNet 1K
- training scheme은 CaiT와 DeiT를 따름
- data augmentation을 위해 MixUp, CutMix, CutOut, RandAugment 사용
- Group Normalization 사용(group number = 1)

Result

- PoolFormer-S24는 21M 매개 변수와 3.6G MACs으로 80% 이상의 top-1 accuracy에 도달함
- 비슷한 성능의 ViT인 DeiT-S는 79.8%의 정확도를 가지지만 28% 더 많은 MACs(4.6G)가 필요함
- MLP-like 모델 ResMLP-S24는 43%(30M) 더 많은 파라미터와 67% 더 많은 연산(6.0G)가 있을 때 79.4의 정확도를 보임
- 개선된 ViT 및 MLP-like 모델과 비교해도 PoolFormer는 여전히 더 나은 성능을 보여줌
- 특히 피라미드 Transformer인 PVT-Medium은 44M 파라미터와 6.7G MAC로 81.2% top-1 정확도를 얻음
- PoolFormer-S36는 PVT-Medium보다 30% 적은 매개변수(31M)와 22% 적은 MAC(5.2G)로 81.5%를 달성함
- ResNet이 동일한 300 epoch동안 개선된 교육 절차로 훈련되는 RSB-ResNet[과 비교할 때, PoolFormer의 성능이 여전히 우수함
- ~22M 파라미터/3.7G MAC의 RSB-ResNet-34는 75.5% 정확도를 얻는 반면, PoolFormer-S24는 80.3%을 얻음
- pooling 연산자를 사용하면 각 토큰이 평균적으로 인접 토큰의 feature를 집계함 → 가장 기본적인 token mixing operation
- 그러나 실험 결과는 이 매우 간단한 token mixer를 사용하더라도 MetaFormer가 여전히 매우 경쟁력 있는 성능을 얻을 수 있음을 보여줌

- PoolFormer가 더 적은 수의 MAC 및 파라미터로 다른 모델의 성능을 능가하는 것을 알 수 있음
- 이 발견은 vision 모델을 설계할 때 실제로 필요한 것이 general 아키텍처 MetaFormer라는 것을 시사함
- MetaFormer를 채택함으로써 파생 모델은 합리적인 성능을 달성할 수 있는 잠재력을 갖출 수 있음
Object detection and instance segmentation
Setup
- COCO
- RetinaNet(object detection), Mask R-CNN(object detection, instance segmentation)의 backbone으로 사용함
Results

- object detection을 위한 RetinaNet이 장착된 PoolFormer 기반 모델은 지속적으로 유사한 ResNet 모델보다 우수한 성능을 보임
- PoolFormer-S12는 ResNet-18(31.8 AP)을 크게 능가하는 36.2 AP를 달성함

- object detection, instance segmentation을 위한 Mask R-CNN을 기반으로 한 모델에서도 유사한 결과를 관찰할 수 있음
- PoolFormer-S12는 ResNet-18(bounding box AP 37.3 vs. 34.0, mask AP 34.6 vs. 31.2)을 크게 능가함
- 전반적으로, COCO object detection 및 instance segmentation에서 PoolForems는 ResNet보다 일관되게 우수한 성능을 보이며 경쟁력을 증명함
Semantic segmentation
Setup
- ADE20K
- Semantic FPN의 backbone으로 사용
Results

- Poolformer 기반 모델은 CNN기반 ResNet/ResNeXt 및 Transformer 기반 PVT 모델의 성능을 일관되게 능가함
- PoolFormer-12는 ResNet-18 및 PVT-Tiny보다 각각 37.1, 4.3 및 1.5의 mIoU를 달성함
- 이러한 결과는 백본 역할을 하는 Poolformer가 토큰 간의 정보 communication을 위해 기본적인 pooling을 사용하지만, semantic segmentation에서 경쟁력 있는 성능을 달성할 수 있음을 보여줌
- 이는 MetaFormer의 잠재력이 크다는 것을 나타내며 MetaFormer가 실제로 필요하다는 논문의 주장을 뒷받침함
Ablation studies

Hybrid stages
- pooling 기반 token mixer는 훨씬 더 긴 입력 시퀀스를 처리할 수 있음
- attention 및 spatial MLP는 전역 정보를 캡쳐하는 데 좋음
- 따라서, 하위 단계에서 pooling이 있는 MetaFormer를 쌓아 긴 시퀀스를 처리하고, 시퀀스가 크게 단축된 것을 고려하여 상위 단계에서 attention 또는 spatial MLP 기반 mixer를 사용하는 것이 직관적임
- 논문에서는 Poolformer의 상위 하나, 두개의 단계에서의 pooling token mixer를 attention 또는 spatial FC로 대체함
- token mixer로 하나의 spatial fully connected layer만 사용 → spatial FC
- [Pool, Pool, Attention, Attention]은 16.5M 파라미터와 2.7G MAC만으로 81.0%의 정확도를 달성함 ↔ ResMLP-B24는 7배의 파라미터(116M)와 8.5배의 MACs(23.0G)일 때 동일한 정확도를 달성함
- 이러한 결과는 MetaFormer에 대한 다른 token mixer와 pooling을 결합하는 것이 성능을 더욱 향상시킬 수 있음을 시사함
Conclusion and future work
- 본 연구에서는 token mixer로 Transformer의 attention을 추상화하고, token mixer가 지정되지 않은 MetaFormer라는 general 아키텍처로 전체 Transformer를 추상화함
- 특정 token mixer에 초점을 맞추는 대신, 실제로 MetaFormer가 합리적인 성능을 달성하는 데 필요하다고 지적함
- 이를 확인하기 위해, 의도적으로 MetaFormer의 token mixer를 매우 간단한 pooling으로 지정함
- PoolFormer 모델은 다양한 가상 작업에서 경쟁력 있는 성능을 달성할 수 있으며, 이는 "MetaFormer is actually what you need for vision"를 잘 뒷받침함
- 향후에는 self-supervised 및 transfer learning등에서 PoolFormer를 추가로 실험할 것
- 또한, NLP 도메인에서 "MetaFormer is actually what you need for vision"이라는 주장을 뒷받침하기 위해 여전히 NLP task에서 유의미한지 확인하는 것은 흥미로움
- 본 논문의 연구가 미래의 연구가 token mixer 모듈에 너무 많은 비용을 지불하는 대신, 기본 아키텍처 MetaFormer을 개선하는 데 전념하도록 영감을 줄 수 있기를 바람
Comments